


Description
Redundancy and failover are critical concepts in network and systems design that aim to ensure high availability, reliability, and continuous service operation. They involve implementing strategies and mechanisms to prevent disruptions and minimize downtime in the event of hardware failures, software issues, or other unforeseen problems. By incorporating redundancy and failover, organizations can maintain service continuity, enhance system resilience, and protect against data loss or outages.
Critical Components of Redundancy and Failover:
- Redundancy:
Definition and Purpose: Redundancy refers to duplicating critical components or systems to create backup resources that can take over in failure. The primary purpose of redundancy is to ensure that no single point of failure could impact the availability or performance of services.
Types of Redundancy:
- Hardware Redundancy involves duplicating physical components such as servers, power supplies, and network devices. For example, using multiple servers in a cluster ensures that others can continue to handle the workload if one fails.
- Network Redundancy: Redundant network connections, switches, and routers provide alternative paths for data traffic, preventing network outages if one link or device fails. Techniques such as load balancing and link aggregation enhance network reliability.
- Data Redundancy: Data redundancy involves creating multiple copies of data to protect against loss. This includes techniques such as RAID (Redundant Array of Independent Disks) and regular backups to offsite storage or cloud-based solutions.
Benefits of Redundancy:
- Increased Reliability: Redundant components ensure that there is always a backup available, enhancing the overall reliability of systems and services.
- Reduced Downtime: By having redundant systems in place, organizations can minimize the impact of failures and reduce the time required for recovery.
- Enhanced Performance: Redundancy can also improve performance by distributing workloads across multiple resources and avoiding overloading a single component.
- Failover:
Definition and Purpose: Failover automatically switches to a backup system or component when the primary one fails. Failover mechanisms ensure that services continue to operate smoothly without significant interruption, even in a failure.
Types of Failover:
- Automatic Failover: This occurs without human intervention. The system detects a failure and automatically switches to the backup component. Automatic failover is typically implemented using clustering software or high-availability systems that monitor the health of components and manage the failover process.
- Manual Failover: In manual failover, human intervention is required to initiate the switch to backup systems. This approach may be used when automatic failover is not feasible, or additional verification is needed before switching.
Failover Mechanisms:
- Heartbeat Monitoring: Heartbeat monitoring involves sending regular signals between primary and backup systems to check their status. The backup system is activated if the primary system fails to send a heartbeat signal.
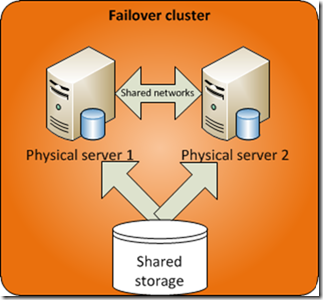
- Failover Clustering: Failover clustering involves grouping multiple servers into a cluster, with one server acting as the primary and others as backups. If the primary server fails, another server in the cluster takes over the role, ensuring continuous operation.
- DNS Failover: DNS failover involves redirecting traffic to an alternate server or data center if the primary server becomes unavailable. DNS failover can be configured to provide geographic redundancy and load balancing.
Benefits of Failover:
- Continuous Availability: Failover mechanisms ensure that services remain available even when a primary component fails, reducing the impact on users and operations.
- Minimized Disruption: Failover processes minimize service disruption by quickly switching to backup resources, allowing for swift recovery and continuity.
- Enhanced User Experience: By maintaining service availability through failover, organizations can provide a reliable user experience and avoid negative impacts on customer satisfaction.
- Design Considerations:
High Availability Design: High availability design integrates redundancy and failover mechanisms into the overall system architecture. This includes designing for fault tolerance, ensuring that critical components have redundant counterparts, and implementing failover procedures.
Testing and Validation: Regular testing of redundancy and failover mechanisms is essential to ensure that they function correctly during actual failures. This includes conducting failover drills, validating backup systems, and verifying that recovery processes work as intended.
Cost and Complexity: Implementing redundancy and failover involves additional costs and complexity, such as procuring redundant hardware, configuring backup systems, and managing failover processes. Balancing the benefits of redundancy with budget constraints and complexity is essential for effective implementation.
Documentation and Training: Comprehensive documentation of redundancy and failover procedures is essential for managing and executing failover operations. Training IT staff and stakeholders on failover processes and recovery steps also ensures preparedness and effective response to failures.

